Kubernetes
in blog on K8s, kubernetes
쿠버네티스 (Kubernetes)
Kubernetes Documentation
Learn about Kubernetes and its fundamental concepts.
- Why Kubernetes?
- Components of a cluster
- The Kubernetes API
- Objects In Kubernetes
- Containers
- Workloads and Pods
Follow tutorials to learn how to deploy applications in Kubernetes.
- Hello Minikube
- Walkthrough the basics
- Stateless Example: PHP Guestbook with Redis
- Stateful Example: Wordpress with Persistent Volumes
Get Kubernetes running based on your resources and needs.
- Learning environment
- Production environment
- Install the kubeadm setup tool
- Securing a cluster
- kubeadm command reference
Look up common tasks and how to perform them using a short sequence of steps.
- kubectl Quick Reference
- Install kubectl
- Configure access to clusters
- Use the Web UI Dashboard
- Configure a Pod to Use a ConfigMap
- Getting help
Browse terminology, command line syntax, API resource types, and setup tool documentation.
- Glossary
- kubectl command line tool
- Labels, annotations and taints
- Kubernetes API reference
- Overview of API
- Feature Gates
Find out how you can help make Kubernetes better.
- Contribute to Kubernetes
- Contribute to documentation
- Suggest content improvements
- Opening a pull request
- Documenting a feature for a release
- Localizing the docs
- Participating in SIG Docs
- Viewing Site Analytics
Get certified in Kubernetes and make your cloud native projects successful!
Install Kubernetes or upgrade to the newest version.
This website contains documentation for the current and previous 4 versions of Kubernetes.
Getting started
- Learning environment
- Production environment
- What’s next
- Download Kubernetes
- Download and install tools including
kubectl - Select a container runtime for your new cluster
- Learn about best practices for cluster setup
Kubernetes is designed for its control plane to run on Linux. Within your cluster you can run applications on Linux or other operating systems, including Windows.
Learn to set up clusters with Windows nodes
- Container Runtimes
Installing Kubernetes with deployment tools
tools descriptions kubeadm Cluster API A Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters. kOps An automated cluster provisioning tool. For tutorials, best practices, configuration options and information on reaching out to the community, please check the kOpswebsite for details.jubespray A composition of Ansible playbooks, inventory, provisioning tools, and domain knowledge for generic OS/Kubernetes clusters configuration management tasks. - Bootstrapping clusters with kubeadm
- Installing kubeadm
- Troubleshooting kubeadm
- Creating a cluster with kubeadm
- Customizing components with the kubeadm API
- Options for Highly Available Topology
- Creating Highly Available Clusters with kubeadm
- Set up a High Availability etcd Cluster with kubeadm
- Configuring each kubelet in your cluster using kubeadm
- Dual-stack support with kubeadm
- Bootstrapping clusters with kubeadm
- Turnkey Cloud Solutions
- Best practices
Concepts
Kubernetes is a portable, extensible, open source platform for managing containerized workloads and services, that facilitates both declarative configuration and automation. It has a large, rapidly growing ecosystem. Kubernetes services, support, and tools are widely available.
Why you need Kubernetes and what it can do.
Features Descriptions Service discovery and load balancing Kubernetes can expose a container using the DNS name or using their own IP address. If traffic to a container is high, Kubernetes is able to load balance and distribute the network traffic so that the deployment is stable. Storage orchestration Kubernetes allows you to automatically mount a storage system of your choice, such as local storages, public cloud providers, and more. Automated rollouts and rollbacks You can describe the desired state for your deployed containers using Kubernetes, and it can change the actual state to the desired state at a controlled rate. For example, you can automate Kubernetes to create new containers for your deployment, remove existing containers and adopt all their resources to the new container. Automatic bin packing You provide Kubernetes with a cluster of nodes that it can use to run containerized tasks. You tell Kubernetes how much CPU and memory (RAM) each container needs. Kubernetes can fit containers onto your nodes to make the best use of your resources. Self-healing Kubernetes restarts containers that fail, replaces containers, kills containers that don’t respond to your user-defined health check, and doesn’t advertise them to clients until they are ready to serve. Secret and configuration management Kubernetes lets you store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configuration without rebuilding your container images, and without exposing secrets in your stack configuration. Batch execution In addition to services, Kubernetes can manage your batch and CI workloads, replacing containers that fail, if desired. Horizontal scaling Scale your application up and down with a simple command, with a UI, or automatically based on CPU usage. IPv4/IPv6 dual-stack Allocation of IPv4 and IPv6 addresses to Pods and Services Designed for extensibility Add features to your Kubernetes cluster without changing upstream source code. What Kubernetes is not
# Kubernetes: 1 Does not limit the types of applications supported. Kubernetes aims to support an extremely diverse variety of workloads, including stateless, stateful, and data-processing workloads. If an application can run in a container, it should run great on Kubernetes. 2 Does not deploy source code and does not build your application. Continuous Integration, Delivery, and Deployment (CI/CD) workflows are determined by organization cultures and preferences as well as technical requirements. 3 Does not provide application-level services, such as middleware (for example, message buses), data-processing frameworks (for example, Spark), databases (for example, MySQL), caches, nor cluster storage systems (for example, Ceph) as built-in services. Such components can run on Kubernetes, and/or can be accessed by applications running on Kubernetes through portable mechanisms, such as the Open Service Broker. 4 Does not dictate logging, monitoring, or alerting solutions. It provides some integrations as proof of concept, and mechanisms to collect and export metrics. 5 Does not provide nor mandate a configuration language/system (for example, Jsonnet). It provides a declarative API that may be targeted by arbitrary forms of declarative specifications. 6 Does not provide nor adopt any comprehensive machine configuration, maintenance, management, or self-healing systems. 7 Additionally, Kubernetes is not a mere orchestration system. In fact, it eliminates the need for orchestration. The technical definition of orchestration is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes comprises a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C. Centralized control is also not required. This results in a system that is easier to use and more powerful, robust, resilient, and extensible. Historical context for Kubernetes
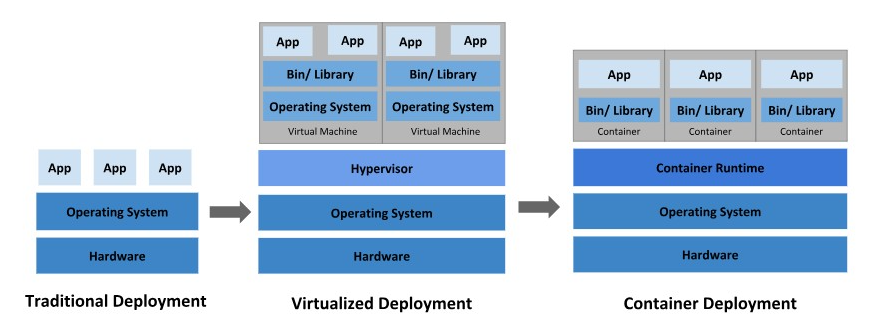
history hescriptions Traditional deployment Early on, organizations ran applications on physical servers. There was no way to define resource boundaries for applications in a physical server, and this caused resource allocation issues. For example, if multiple applications run on a physical server, there can be instances where one application would take up most of the resources, and as a result, the other applications would underperform. A solution for this would be to run each application on a different physical server. But this did not scale as resources were underutilized, and it was expensive for organizations to maintain many physical servers. Virtualized deployment As a solution, virtualization was introduced. It allows you to run multiple Virtual Machines (VMs) on a single physical server’s CPU. Virtualization allows applications to be isolated between VMs and provides a level of security as the information of one application cannot be freely accessed by another application.</br></br>Virtualization allows better utilization of resources in a physical server and allows better scalability because an application can be added or updated easily, reduces hardware costs, and much more. With virtualization you can present a set of physical resources as a cluster of disposable virtual machines.</br></br>Each VM is a full machine running all the components, including its own operating system, on top of the virtualized hardware. Container deployment Containers are similar to VMs, but they have relaxed isolation properties to share the Operating System (OS) among the applications. Therefore, containers are considered lightweight. Similar to a VM, a container has its own filesystem, share of CPU, memory, process space, and more. As they are decoupled from the underlying infrastructure, they are portable across clouds and OS distributions.</br></br>Containers have become popular because they provide extra benefits, such as:</br></br>- Agile application creation and deployment: increased ease and efficiency of container image creation compared to VM image use.</br>- Continuous development, integration, and deployment: provides for reliable and frequent container image build and deployment with quick and efficient rollbacks (due to image immutability).</br>- Dev and Ops separation of concerns: create application container images at build/release time rather than deployment time, thereby decoupling applications from infrastructure.</br>- Observability: not only surfaces OS-level information and metrics, but also application health and other signals.</br>- Environmental consistency across development, testing, and production: runs the same on a laptop as it does in the cloud.</br>- Cloud and OS distribution portability: runs on Ubuntu, RHEL, CoreOS, on-premises, on major public clouds, and anywhere else.</br>- Application-centric management: raises the level of abstraction from running an OS on virtual hardware to running an application on an OS using logical resources.</br>- Loosely coupled, distributed, elastic, liberated micro-services: applications are broken into smaller, independent pieces and can be deployed and managed dynamically – not a monolithic stack running on one big single-purpose machine.</br>- Resource isolation: predictable application performance.</br>- Resource utilization: high efficiency and density Kubernetes Components
An overview of the key components that make up a Kubernetes cluster.
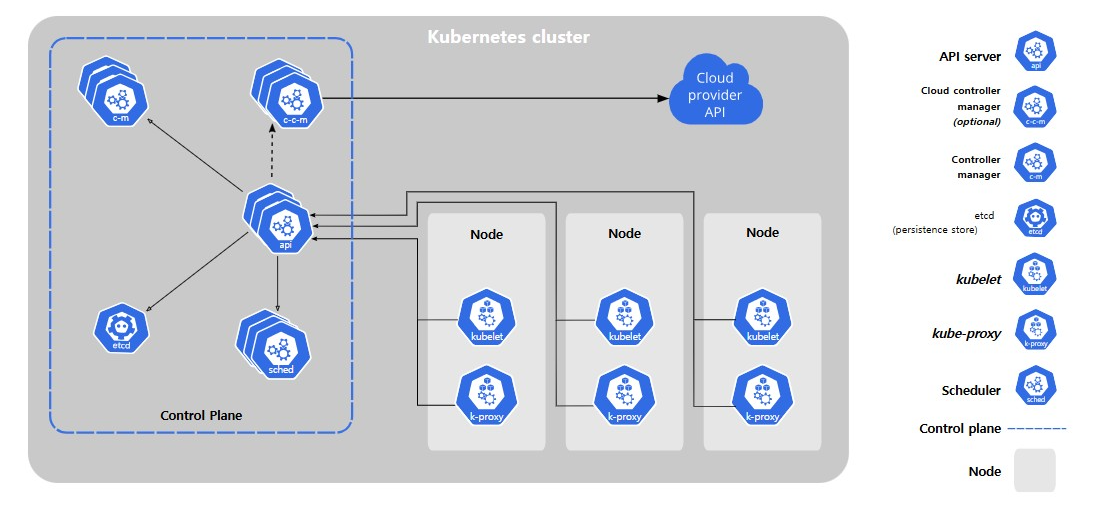
Core Components
A Kubernetes cluster consists of a control plane and one or more worker nodes. Here’s a brief overview of the main components:
Control Plane Components
Manage the overall state of the cluster:
components descriptions kube-apiserver The core component server that exposes the Kubernetes HTTP API etcd Consistent and highly-available key value store for all API server data kube-scheduler Looks for Pods not yet bound to a node, and assigns each Pod to a suitable node. kube-controller-manager Runs controllers to implement Kubernetes API behavior. cloud-controller-manager (optional) Integrates with underlying cloud provider(s) Node Components
Run on every node, maintaining running pods and providing the Kubernetes runtime environment:
components descriptions kubelet Ensures that Pods are running, including their containers. kube-proxy (optional) Maintains network rules on nodes to implement Services. Container runtime Software responsible for running containers. Read Container Runtimes to learn more. Addons
Addons extend the functionality of Kubernetes. A few important examples include:
components descriptions DNS For cluster-wide DNS resolution Web UI (Dashboard) For cluster management via a web interface Container Resource Monitoring For collecting and storing container metrics Cluster-level Logging For saving container logs to a central log store
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster. Learn about the Kubernetes object model and how to work with these objects.
This page explains how Kubernetes objects are represented in the Kubernetes API, and how you can express them in.yamlformat.Understanding Kubernetes objects
Kubernetes objects are persistent entities in the Kubernetes system. Kubernetes uses these entities to represent the state of your cluster. Specifically, they can describe:
- What containerized applications are running (and on which nodes) - The resources available to those applications - The policies around how those applications behave, such as restart policies, upgrades, and fault-toleranceObject spec and status
Almost every Kubernetes object includes two nested object fields that govern the object's configuration: the object `spec` and the object `status`. For objects that have a `spec`, you have to set this when you create the object, providing a description of the characteristics you want the resource to have: its desired `state`.Describing a Kubernetes object
When you create an object in Kubernetes, you must provide the object spec that describes its desired state, as well as some basic information about the object (such as a name). When you use the Kubernetes API to create the object (either directly or via kubectl), that API request must include that information as JSON in the request body. Here's an example manifest that shows the required fields and object spec for a Kubernetes Deployment:apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 2 # tells deployment to run 2 pods matching the template template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80kubectl apply -f https://k8s.io/examples/application/deployment.yaml deployment.apps/nginx-deployment createdRequired fields
In the manifest (YAML or JSON file) for the Kubernetes object you want to create, you’ll need to set values for the following fields:
fields descriptions apiVersionWhich version of the Kubernetes API you’re using to create this object kindWhat kind of object you want to create metadataData that helps uniquely identify the object, including a namestring, UID, and optionalnamespacespecWhat state you desire for the object Server side field validation
Starting with Kubernetes v1.25, the API server offers server side field validation that detects unrecognized or duplicate fields in an object. It provides all the functionality of
kubectl --validateon the server side.fields descriptions Strict Strict field validation, errors on validation failure Warn Field validation is performed, but errors are exposed as warnings rather than failing the request Ignore No server side field validation is performed - Kubernetes Object Management
- Imperative object configuration: In imperative object configuration, the kubectl command specifies the operation (create, replace, etc.), optional flags and at least one file name. The file specified must contain a full definition of the object in YAML or JSON format.
API reference
object configuration descriptions Create the objects defined in a configuration file kubectl create -f nginx.yaml Delete the objects defined in two configuration files kubectl delete -f nginx.yaml -f redis.yaml Update the objects defined in a configuration file by overwriting the live configuration kubectl replace -f nginx.yaml - Declarative object configuration: When using declarative object configuration, a user operates on object configuration files stored locally, however the user does not define the operations to be taken on the files. Create, update, and delete operations are automatically detected per-object by
kubectl. This enables working on directories, where different operations might be needed for different objects.
Examples
Process all object configuration files in the configs directory, and create or patch the live objects. You can first diff to see what changes are going to be made, and then apply:
kubectl diff -f configs/ kubectl apply -f configs/Recursively process directories:
kubectl diff -R -f configs/ kubectl apply -R -f configs/ - Imperative object configuration: In imperative object configuration, the kubectl command specifies the operation (create, replace, etc.), optional flags and at least one file name. The file specified must contain a full definition of the object in YAML or JSON format.
Each object in your cluster has a Name that is unique for that type of resource. Every Kubernetes object also has a UID that is unique across your whole cluster.
For example, you can only have one Pod named
myapp-1234within the same namespace, but you can have one Pod and one Deployment that are each namedmyapp-1234.Names
A client-provided string that refers to an object in a resource URL, such as
/api/v1/pods/some-name.
Only one object of a given kind can have a given name at a time. However, if you delete the object, you can make a new object with the same name.Names must be unique across all API versions of the same resource. API resources are distinguished by their API group, resource type, namespace (for namespaced resources), and name. In other words, API version is irrelevant in this context.
DNS Subdomain Names
Most resource types require a name that can be used as a DNS subdomain name as defined in RFC 1123. This means the name must:
- contain no more than 253 characters
- contain only lowercase alphanumeric characters, ‘-‘ or ‘.’
- start with an alphanumeric character
- end with an alphanumeric character
RFC 1123 Label Names
Some resource types require their names to follow the DNS label standard as defined in RFC 1123. This means the name must:
- contain at most 63 characters
- contain only lowercase alphanumeric characters or ‘-‘
- start with an alphanumeric character
- end with an alphanumeric character
RFC 1035 Label Names
Some resource types require their names to follow the DNS label standard as defined in RFC 1035. This means the name must:
- contain at most 63 characters
- contain only lowercase alphanumeric characters or ‘-‘
- start with an alphabetic character
- end with an alphanumeric character
Path Segment Names
Some resource types require their names to be able to be safely encoded as a path segment. In other words, the name may not be “.” or “..” and the name may not contain “/” or “%”.
apiVersion: v1 kind: Pod metadata: name: nginx-demo spec: containers: - name: nginx image: nginx:1.14.2 ports: - containerPort: 80
UIDs
A Kubernetes systems-generated string to uniquely identify objects.
Every object created over the whole lifetime of a Kubernetes cluster has a distinct UID. It is intended to distinguish between historical occurrences of similar entities.
Kubernetes UIDs are universally unique identifiers (also known as UUIDs). UUIDs are standardized as ISO/IEC 9834-8 and as ITU-T X.667.
- Labels and Selectors
- Namespaces
- Annotations
- Field Selectors
- Finalizers
- Owners and Dependents
- Recommended Labels
- Kubernetes Object Management
The Kubernetes API
- Cluster Architecture
- Nodes
- Communication between Nodes and the Control Plane
- Controllers
- Leases
- Cloud Controller Manager
- About cgroup v2
- Container Runtime Interface (CRI)
- Garbage Collection
- Mixed Version Proxy
- Containers
- Images
- Container Environment
- Runtime Class
- Container Lifecycle Hooks
- Workloads
- Pods
- Pod Lifecycle
- Init Containers
- Sidecar Containers
- Ephemeral Containers
- Disruptions
- Pod Quality of Service Classes
- User Namespaces
- Downward API
- Workload Management
- Deployments
- ReplicaSet
- StatefulSets
- DaemonSetJobs
- Automatic Cleanup for Finished Jobs
- CronJob
- ReplicationController
- Autoscaling Workloads
- Managing Workloads
- Pods
- Services, Load Balancing, and Networking
- Service
- Ingress
- Ingress Controllers
- Gateway API
- EndpointSlices
- Network Policies
- DNS for Services and Pods
- IPv4/IPv6 dual-stack
- Topology Aware Routing
- Networking on Windows
- Service ClusterIP allocation
- Service Internal Traffic Policy
- Storage
- Volumes
- Persistent Volumes
- Projected Volumes
- Ephemeral Volumes
- Storage Classes
- Volume Attributes Classes
- Dynamic Volume Provisioning
- Volume Snapshots
- Volume Snapshot Classes
- CSI Volume Cloning
- Storage Capacity
- Node-specific Volume Limits
- Volume Health Monitoring
- Windows Storage
- Configuration
- Configuration Best Practices
- ConfigMaps
- Secrets
- Liveness, Readiness, and Startup Probes
- Resource Management for Pods and Containers
- Organizing Cluster Access Using kubeconfig Files
- Resource Management for Windows nodes
- Security
- Cloud Native Security and Kubernetes
- Pod Security Standards
- Pod Security Admission
- Service Accounts
Pod Security Policies- Security For Windows Nodes
- Controlling Access to the Kubernetes API
- Role Based Access Control Good Practices
- Good practices for Kubernetes Secrets
- Multi-tenancy
- Hardening Guide - Authentication Mechanisms
- Kubernetes API Server Bypass Risks
- Linux kernel security constraints for Pods and containers
- Security Checklist
- Application Security Checklist
- Policies
- Limit Ranges
- Resource Quotas
- Process ID Limits And Reservations
- Node Resource Managers
- Scheduling, Preemption and Eviction
- Kubernetes Scheduler
- Assigning Pods to Nodes
- Pod Overhead
- Pod Topology Spread Constraints
- Taints and Tolerations
- Scheduling Framework
- Dynamic Resource Allocation
- Scheduler Performance Tuning
- Resource Bin Packing for Extended Resources
- Pod Priority and Preemption
- Node-pressure Eviction
- API-initiated Eviction
- Cluster Administration
- Node Shutdowns
- Certificates
- Cluster Networking
- Logging Architecture
- Metrics For Kubernetes System Components
- Metrics for Kubernetes Object States
- System Logs
- Traces For Kubernetes System Components
- Proxies in Kubernetes
- API Priority and Fairness
- Cluster Autoscaling
- Installing Addons
- Coordinated Leader Election
- Windows in Kubernetes
- Windows containers in Kubernetes
- Guide for Running Windows Containers in Kubernetes
- Extending Kubernetes
- Compute, Storage, and Networking Extensions
- Extending the Kubernetes API
- Operator pattern
Tasks
Install Tools
Tools Descriptions kubectl The Kubernetes command-line tool, kubectl, allows you to run commands against Kubernetes clusters. You can use kubectl to deploy applications, inspect and manage cluster resources, and view logs kind kind lets you run Kubernetes on your local computer. This tool requires that you have either Docker or Podman installed. view minikube Like kind, minikube is a tool that lets you run Kubernetes locally. minikube runs an all-in-one or a multi-node local Kubernetes cluster on your personal computer (including Windows, macOS and Linux PCs) so that you can try out Kubernetes, or for daily development work. view kubeadm You can use the kubeadm tool to create and manage Kubernetes clusters. It performs the actions necessary to get a minimum viable, secure cluster up and running in a user friendly way. view - Administer a Cluster
- Administration with kubeadm
- Adding Linux worker nodes
- Adding Windows worker nodes
- Upgrading kubeadm clusters
- Upgrading Linux nodes
- Upgrading Windows nodes
- Configuring a cgroup driver
- Certificate Management with kubeadm
- Reconfiguring a kubeadm cluster
- Changing The Kubernetes Package Repository
- Overprovision Node Capacity For A Cluster
- Migrating from dockershim
- Changing the Container Runtime on a Node from Docker Engine to containerd
- Migrate Docker Engine nodes from dockershim to cri-dockerd
- Find Out What Container Runtime is Used on a Node
- Troubleshooting CNI plugin-related errors
- Check whether dockershim removal affects you
- Migrating telemetry and security agents from dockershim
- Generate Certificates Manually
- Manage Memory, CPU, and API Resources
- Configure Default Memory Requests and Limits for a Namespace
- Configure Default CPU Requests and Limits for a Namespace
- Configure Minimum and Maximum Memory Constraints for a Namespace
- Configure Minimum and Maximum CPU Constraints for a Namespace
- Configure Memory and CPU Quotas for a Namespace
- Configure a Pod Quota for a Namespace
- Install a Network Policy Provider
- Use Antrea for NetworkPolicy
- Use Calico for NetworkPolicy
- Use Cilium for NetworkPolicy
- Use Kube-router for NetworkPolicy
- Romana for NetworkPolicy
- Weave Net for NetworkPolicy
- Access Clusters Using the Kubernetes API
- Advertise Extended Resources for a Node
- Autoscale the DNS Service in a Cluster
- Change the Access Mode of a PersistentVolume to ReadWriteOncePod
- Change the default StorageClass
- Switching from Polling to CRI Event-based Updates to Container Status
- Change the Reclaim Policy of a PersistentVolume
- Cloud Controller Manager Administration
- Configure a kubelet image credential provider
- Configure Quotas for API Objects
- Control CPU Management Policies on the Node
- Control Topology Management Policies on a node
- Customizing DNS Service
- Debugging DNS Resolution
- Declare Network Policy
- Developing Cloud Controller Manager
- Enable Or Disable A Kubernetes API
- Encrypting Confidential Data at Rest
- Decrypt Confidential Data that is Already Encrypted at Rest
- Guaranteed Scheduling For Critical Add-On Pods
- IP Masquerade Agent User Guide
- Limit Storage Consumption
- Migrate Replicated Control Plane To Use Cloud Controller Manager
- Namespaces Walkthrough
- Operating etcd clusters for Kubernetes
- Reserve Compute Resources for System Daemons
- Running Kubernetes Node Components as a Non-root User
- Safely Drain a Node
- Securing a Cluster
- Set Kubelet Parameters Via A Configuration File
- Share a Cluster with Namespaces
- Upgrade A Cluster
- Use Cascading Deletion in a Cluster
- Using a KMS provider for data encryption
- Using CoreDNS for Service Discovery
- Using NodeLocal DNSCache in Kubernetes Clusters
- Using sysctls in a Kubernetes Cluster
- Utilizing the NUMA-aware Memory Manager
- Verify Signed Kubernetes Artifacts
- Administration with kubeadm
- Configure Pods and Containers
- Assign Memory Resources to Containers and Pods
- Assign CPU Resources to Containers and Pods
- Configure GMSA for Windows Pods and containers
- Resize CPU and Memory Resources assigned to Containers
- Configure RunAsUserName for Windows pods and containers
- Create a Windows HostProcess Pod
- Configure Quality of Service for Pods
- Assign Extended Resources to a Container
- Configure a Pod to Use a Volume for Storage
- Configure a Pod to Use a PersistentVolume for Storage
- Configure a Pod to Use a Projected Volume for Storage
- Configure a Security Context for a Pod or Container
- Configure Service Accounts for Pods
- Pull an Image from a Private Registry
- Configure Liveness, Readiness and Startup Probes
- Assign Pods to Nodes
- Assign Pods to Nodes using Node Affinity
- Configure Pod Initialization
- Attach Handlers to Container Lifecycle Events
- Configure a Pod to Use a ConfigMap
- Share Process Namespace between Containers in a Pod
- Use a User Namespace With a Pod
- Use an Image Volume With a Pod
- Create static Pods
- Translate a Docker Compose File to Kubernetes Resources
- Enforce Pod Security Standards by Configuring the Built-in Admission Controller
- Enforce Pod Security Standards with Namespace Labels
- Migrate from PodSecurityPolicy to the Built-In PodSecurity Admission Controller
- Monitoring, Logging, and Debugging
- Troubleshooting Applications
- Debug Pods
- Debug Services
- Debug a StatefulSet
- Determine the Reason for Pod Failure
- Debug Init Containers
- Debug Running Pods
- Get a Shell to a Running Container
- Troubleshooting Clusters
- Troubleshooting kubectl
- Resource metrics pipeline
- Tools for Monitoring Resources
- Monitor Node Health
- Debugging Kubernetes nodes with crictl
- Auditing
- Debugging Kubernetes Nodes With Kubectl
- Developing and debugging services locally using telepresence
- Windows debugging tips
- Troubleshooting Applications
- Manage Kubernetes Objects
- Declarative Management of Kubernetes Objects Using Configuration Files
- Declarative Management of Kubernetes Objects Using Kustomize
- Managing Kubernetes Objects Using Imperative Commands
- Imperative Management of Kubernetes Objects Using Configuration Files
- Update API Objects in Place Using kubectl patch
- Migrate Kubernetes Objects Using Storage Version Migration
- Managing Secrets
- Managing Secrets using kubectl
- Managing Secrets using Configuration File
- Managing Secrets using Kustomize
- Inject Data Into Applications
- Define a Command and Arguments for a Container
- Define Dependent Environment Variables
- Define Environment Variables for a Container
- Expose Pod Information to Containers Through Environment Variables
- Expose Pod Information to Containers Through Files
- Distribute Credentials Securely Using Secrets
- Run Applications
- Run a Stateless Application Using a Deployment
- Run a Single-Instance Stateful Application
- Run a Replicated Stateful Application
- Scale a StatefulSet
- Delete a StatefulSet
- Force Delete StatefulSet Pods
- Horizontal Pod Autoscaling
- HorizontalPodAutoscaler Walkthrough
- Specifying a Disruption Budget for your Application
- Accessing the Kubernetes API from a Pod
- Run Jobs
- Running Automated Tasks with a CronJob
- Coarse Parallel Processing Using a Work Queue
- Fine Parallel Processing Using a Work Queue
- Indexed Job for Parallel Processing with Static Work Assignment
- Job with Pod-to-Pod Communication
- Parallel Processing using Expansions
- Handling retriable and non-retriable pod failures with Pod failure policy
- Access Applications in a Cluster
- Deploy and Access the Kubernetes Dashboard
- Accessing Clusters
- Configure Access to Multiple Clusters
- Use Port Forwarding to Access Applications in a Cluster
- Use a Service to Access an Application in a Cluster
- Connect a Frontend to a Backend Using Services
- Create an External Load Balancer
- List All Container Images Running in a Cluster
- Set up Ingress on Minikube with the NGINX Ingress Controller
- Communicate Between Containers in the Same Pod Using a Shared Volume
- Configure DNS for a Cluster
- Access Services Running on Clusters
- Extend Kubernetes
- Configure the Aggregation Layer
- Use Custom Resources
- Extend the Kubernetes API with CustomResourceDefinitions
- Versions in CustomResourceDefinitions
- Set up an Extension API Server
- Configure Multiple Schedulers
- Use an HTTP Proxy to Access the Kubernetes API
- Use a SOCKS5 Proxy to Access the Kubernetes API
- Set up Konnectivity service
- TLS
- Configure Certificate Rotation for the Kubelet
- Manage TLS Certificates in a Cluster
- Manual Rotation of CA Certificates
- Manage Cluster Daemons
- Perform a Rolling Update on a DaemonSet
- Perform a Rollback on a DaemonSet
- Running Pods on Only Some Nodes
- Networking
- Adding entries to Pod /etc/hosts with HostAliases
- Extend Service IP Ranges
- Validate IPv4/IPv6 dual-stack
- Extend kubectl with plugins
- Manage HugePages
- Schedule GPUs
Tutorials
- Hello Minikube
- Learn Kubernetes Basics
- Create a Cluster
- Deploy an App
- Explore Your App
- Expose Your App Publicly
- Scale Your App
- Update Your App
- Configuration
- Updating Configuration via a ConfigMap
- Configuring Redis using a ConfigMap
- Adopting Sidecar Containers
- Security
- Apply Pod Security Standards at the Cluster Level
- Apply Pod Security Standards at the Namespace Level
- Restrict a Container’s Access to Resources with AppArmor
- Restrict a Container’s Syscalls with seccomp
- Stateless Applications
- Exposing an External IP Address to Access an Application in a Cluster
- Example: Deploying PHP Guestbook application with Redis
- Stateful Applications
- StatefulSet Basics
- Example: Deploying WordPress and MySQL with Persistent Volumes
- Example: Deploying Cassandra with a StatefulSet
- Running ZooKeeper, A Distributed System Coordinator
- Cluster Management
- Running Kubelet in Standalone Mode
- Services
- Connecting Applications with Services
- Using Source IP
- Explore Termination Behavior for Pods And Their Endpoints
Reference
- Glossary
- API Overview
- API Access Control
- Well-Known Labels, Annotations and Taints
- Kubernetes API
- Instrumentation
- Kubernetes Issues and Security
- Node Reference Information
- Networking Reference
- Setup tools
- Command line tool (kubectl)
- Component tools
- Debug cluster
- Configuration APIs
- External APIs
- Scheduling
- Other Tools
Contribute to Kubernetes
- Contribute to Kubernetes Documentation
- Suggesting content improvements
- Contributing new content
- Opening a pull request
- Documenting for a release
- Blogs and case studies
- Reviewing changes
- Reviewing pull requests
- For approvers and reviewers
- Localizing Kubernetes documentation
- Participating in SIG Docs
- Roles and responsibilities
- Issue Wranglers
- PR wranglers
- Documentation style overview
- Content guide
- Style guide
- Diagram guide
- Writing a new topic
- Page content types
- Content organization
- Custom Hugo Shortcodes
- Updating Reference Documentation
- Quickstart
- Contributing to the Upstream Kubernetes Code
- Generating Reference Documentation for the Kubernetes API
- Generating Reference Documentation for kubectl Commands
- Generating Reference Documentation for Metrics
- Generating Reference Pages for Kubernetes Components and Tools
- Advanced contributing
- Viewing Site Analytics