Kubernetes
in blog on Cloud
Kubernetes 개요
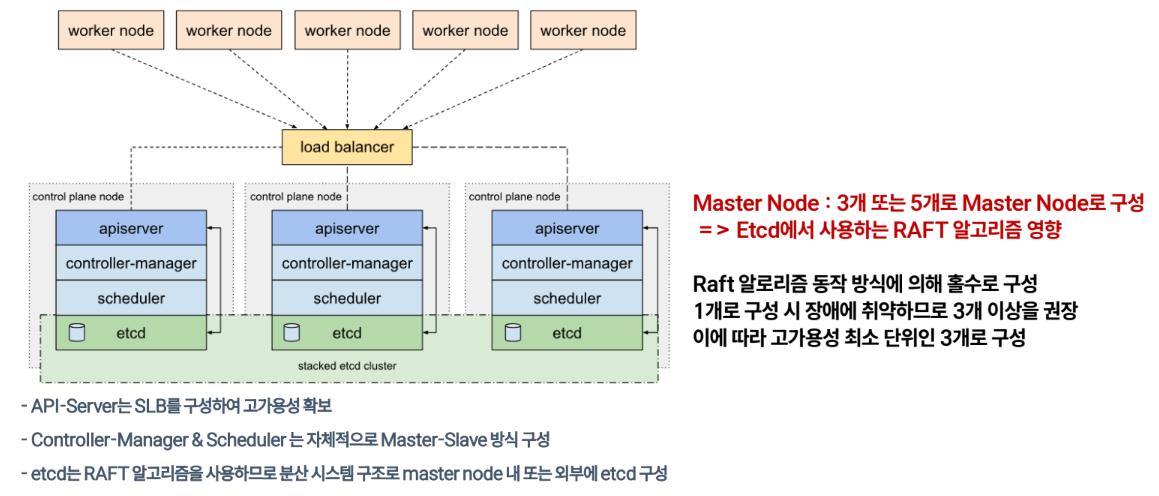
k8s Cluster 구조
Kubernetes Cluster 컴포넌트 구성
마스터노드
컴포넌트 설명 etcd key-value 타입의 저장소</br>쿠버네티스 마스터 및 노드들의 다양한 상태 정보 저장 kube-apiserver k8s API를 사용하도록 요청을 받고 요청이 유효한지 검사 kube-scheduler 파드를 실행할 노드 선택 kube-controller-manager 파드를 관찰하며 개수를 보장 워커노드
컴포넌트 설명 kubelet - 모든 노드에서 실행되는 k8s 에이전트</br>데몬 형태로 동작 kube-proxy k8s의 network 동작을 관리</br>iptables rule을 구성 컨테이너 런타임 컨테이너를 실행하는 엔진</br>docker, containerd, runc
Kubernetes Cluster 컴포넌트 Overview
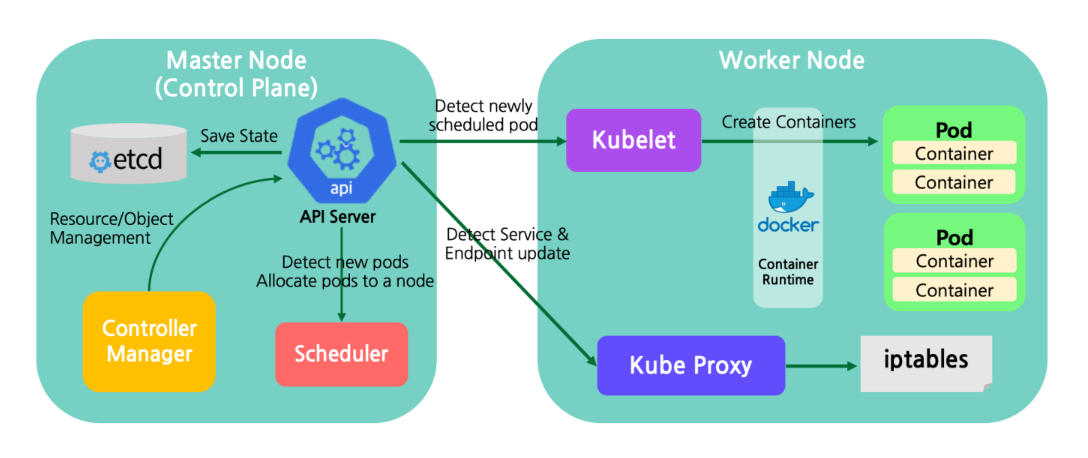
Component name Comunicates with Role kube-apiserver kubectl client(s), Etcd, kube-scheduler, kube-controller-manager,Kubelet, kube-proxy HTTP REST API로 etcd에 있는 state를 R/W. (이 component만이 직접 Etcd에 접근가능) Etcd kube-apiserver 매 20초간 스케줄링되지 않은 pod들을 읽어오는 API를 kube-apiserver에게 전달. 이후 스케줄링되지 않은 pod들의 property인 nodeName을 변경하여 worker node에 스케줄링 kube-scheduler kube-apiserver API를 polling하고 reconcilation loop를 동작 kube-controller-manager kube-apiserver kube-apiserver에게 20초마다 kubelet이 동작하는 worker node에 스케줄링된 pod spec들을 가져오는 API를 전송하고, local Docker daemon을 실행하여 해당 worker node에 스케줄링된 pod spec을 동작하는 container로 바꿔줌 kubelet kube-apiserver and Docker (container runtime) kube-proxy kube-apiserver kubernetes의 networking layer를 구현 Container Engine kubelet local Kubelet으로부터 명령어를 받아 container들을 실행 Master Node 고가용성
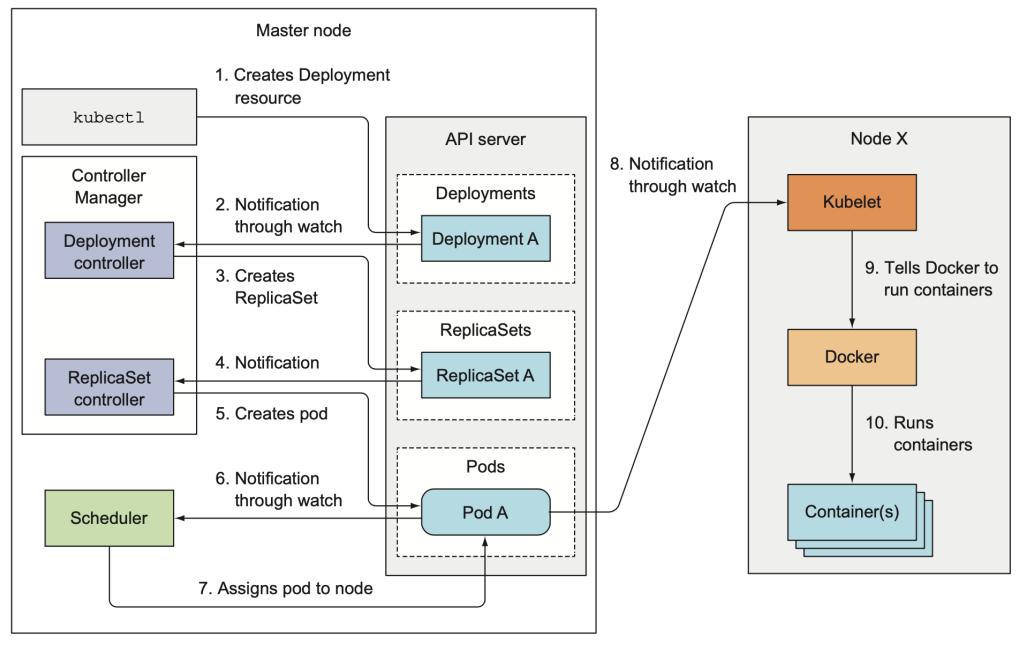
Pod 배포
Controller Manager - Overview
구분 파드유형 워크로드 컨트롤러 고유 데이터 관리/주소 불필요 스테이트리스 Stateless 서버 Deployment 고유 데이터 관리/주소 필요 스테이트풀 Stateful서버 Statefulset 백그라운드 프로세스 필요 데몬 서버 DaemonSet 어떤 처리를 하고 종료 일회성 잡Job 수행 서버 Job 어떤 처리를 주기적으로 수행 배치성 잡Job 수행 서버 CronJob Controller Manager - Stateless와 Stateful 개념
구분 설명 Stateless Application 클라이언트와 서버 관계에서, 서버가 클라이언트의 상태를 보존하지 않는 형태의 서비스</br>대표적으로 Apache, Nginx와 같은 Web server Application</br>Stateless 애플리케이션은 쿠버네티스에서 삭제/생성 시 App의 이름과 상관없이 같은 역할을 하는 애플리케이션만 생성</br>쿠버네티스에서는 Replication Controller, Replicaset, Deployment와 같은 컨트롤러를 이용하여 Stateless 파드 관리 Stateful Application 클라이언트와 서버 관계에서, 서버가 클라이언트의 상태를 보존하는 형태의 Application (대표적으로 DB) Controller Manager - Deployment (Stateless App 배포 시 가장 기본인 컨트롤러)
구분 설명 디플로이먼트(Deployment) 쿠버네티스가 처음 등장했을 때는 Replication Controller에서 앱을 배포했는데 최근에는 디플로이먼트를 기본적적인 앱 배포에 사용</br>기존 Replication Controller 이나 레플리카셋은 ‘이력’이라는 개념이 없어 배포 후 애플리케이션 관리에 어려움이 많았음.</br></br>디플로이먼트 장점:</br>- 배포 기능을 세분화하여 레플리카셋에 버전 관리 기능 추가</br>- 파드 개수 유지 기능</br>- 앱을 배포할 때 롤링 업데이트 하거나, 앰 배포 도중 잠시 멈췄다가 다시 배포 기능</br>- 앱 배포 후 이전 버전으로 롤백 기능</br></br>레플리카셋과 완전히 다른 기능이라고 보기는 어렵고, 디플로이먼트가 레플리카셋을 관리하며 앱 배포를 더 세밀하게 관리하는 것이라고 할 수 있음. Controller Manager – Stateful Set (Stateful App 배포 시 가장 기본인 컨트롤러), 서버가 클라이언트의 상태를 보존하는 형태의 애플리케이션으로 Mongodb, redis와 같은 Database가 대표적임.
구분 설명 Stateful Set 쿠버네티스가 처음 등장했을 때는 Replication Controller에서 앱을 배포했는데 최근에는 디플로이먼트를 기본적적인 앱 배포에 사용</br>기존 Replication Controller 이나 레플리카셋은 ‘이력’이라는 개념이 없어 배포 후 애플리케이션 관리에 어려움이 많았음.</br></br>디플로이먼트 장점:</br>- 배포 기능을 세분화하여 레플리카셋에 버전 관리 기능 추가</br>- 파드 개수 유지 기능</br>- 앱을 배포할 때 롤링 업데이트 하거나, 앰 배포 도중 잠시 멈췄다가 다시 배포 기능</br>- 앱 배포 후 이전 버전으로 롤백 기능</br></br>레플리카셋과 완전히 다른 기능이라고 보기는 어렵고, 디플로이먼트가 레플리카셋을 관리하며 앱 배포를 더 세밀하게 관리하는 것이라고 할 수 있음. Controller Manager – DaemonSet (클러스터 전체 노드에 특정 파드 배포 시 사용)
구분 설명 Daemon Set 클러스터 안에 새롭게 노드가 추가되었을 때 데몬셋이 자동으로 해당 노드에 파드를 실행</br>반대로 노드가 클러스터에서 빠졌을 때는 해당 노드에 있던 파드는 그대로 사라질 뿐 다른 곳으로 옮겨가서 실행되지 않음</br></br>단, 특정 노드에만 Pod를 배포할 수 있도록 , Pod의 “node selector”를 이용하여 특정 노드만을 선택할 수 있음</br>서버의 모니터링이나 로그 수집 용도로 많이 사용 Controller Manager – Job / CronJob (실행된 후 종료해야 하는 성격의 작업을 실행시킬 때 사용), 정해진 타이밍에 반복할 Job 실행에 사용
구분|설명
—|—
Job|하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료될 때 까지 계속해서
파드의 실행을 재시도</br>지정된 수 만큼 파드가 성공적으로 완료되면 Job 완료</br>데이터베이스 마이그레이션과 같이 한 번의 잡으로 처리가 끝나는 것에 이용Controller Manager – Pod 배포 Flow
Pod내 Multi Container 구성
| 구분 | 설명 |
|---|---|
| 원칙 | ✓ 하나의 Pod 내 Multi Container는 서로 다른 종류여야 함</br>✓ Multi Container들은 같은 네트워크 공간을 공유하기 때문에 직접적으로 커뮤니케이션이 가능 |
| 특징 | Pod 내 컨테이너들은 IP와 Port 공유</br>Pod 내에 배포된 컨테이너 간에는 디스크 볼륨 공유 |
| 패턴 | Sidecar Pattern,</br>Ambassador Pattern,</br>Adapter Pattern |
✓ 멀티컨테이너 디지이너 패턴: “하나의 컨테이너에는 하나의 책임만 가지고 있어야 한다.”
| 패턴 | 설명 |
|---|---|
| Sidecar | 메인컨테이너의 기능을 확장 또는 향상, 웹서비스와 로그기능 분리 |
| Ambassador | 메인컨테이너의 네트워크기능 담당, 네트워크연결을 담당하는 전용 컨테이너 |
| Adapter | 메인컨테이너의 출력을 변환, 모니터링 정보를 제공하는 전용 컨테이너 |
Q: ISTIO에서 Envoy는 네트워크 기능을 제공하는데 왜 Sidecar Pattern으로 분류하나?
A: Envoy는 단순 네트워크 연결만이 아닌 제어 등에도 관여함.</br>즉, 컨테이너가 어떤 목적을 가지고 메인컨테이너를 보조하는지에 따라 패턴 분류
- Kubernetes Autoscaler
| 오토스케일러 | 설명 | 비고 |
|---|---|---|
| HPA(Horizontal Pod Autoscaler) | Stateless Application (Scale Out)</br></br>HPA 적용 가능한 Pod 리소스</br>- Deployment</br>- ReplicaSet</br>- Replication Controller</br>- StatefulSet | DaemonSet에는 적용 불가 |
| VPA(Vertical Pod Autoscaler) | Stateful Application (Scale Up) | |
| CA(Cluster Autoscaler) | Multi Cloud |
Kubernetes Autoscaler – HPA 동작
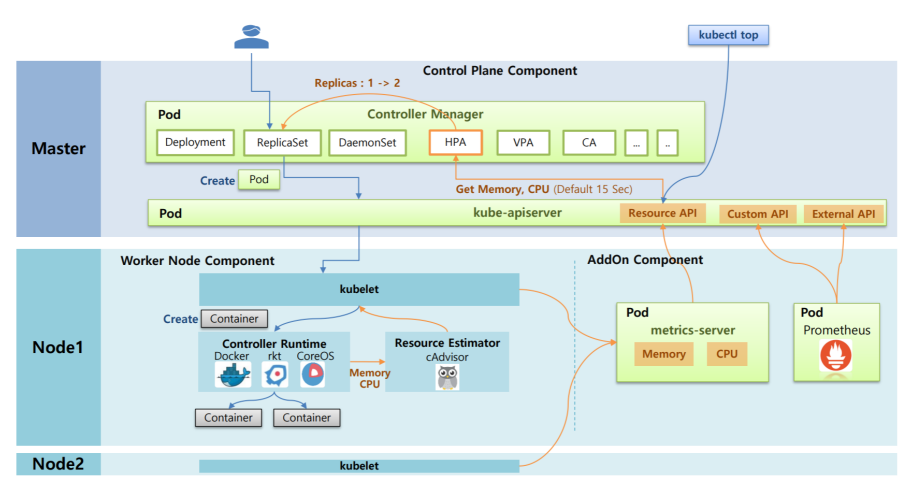
단계 설명 1 Resource Estimator인 cAdvisor가 도커로 부터 메모리와 CPU에 대한 성능 정보를 측정. 이 정보를 kubelet을 통해 가져감 2 AddOn Component로 metrics-server를 설치하면 metrics-server가 각각의 Node에 있는 kubelet에게 메모리와 CPU 정보를 가져와서 저장 3 이 데이터들을 다른 Component들이 사용할 수 있도록 Kube API서버(Resource API)에 등록 4 HPA는 Kube API서버를 통해 메모리와 CPU 정보를 15초마다 체크하다 Pod의 Resources 사용률이 높아지면 replicaSet의 replicas를 증가시킴 5 kubectl top 명령어를 통해서 Resource API를 통해서 Pod나 Node의 Resources 상태를 조회 6 추가적으로 Prometheus를 사용하면 메모리와 CPU 외에도 다른 metric 정보를 수집(패킷 수, Request 양 등) 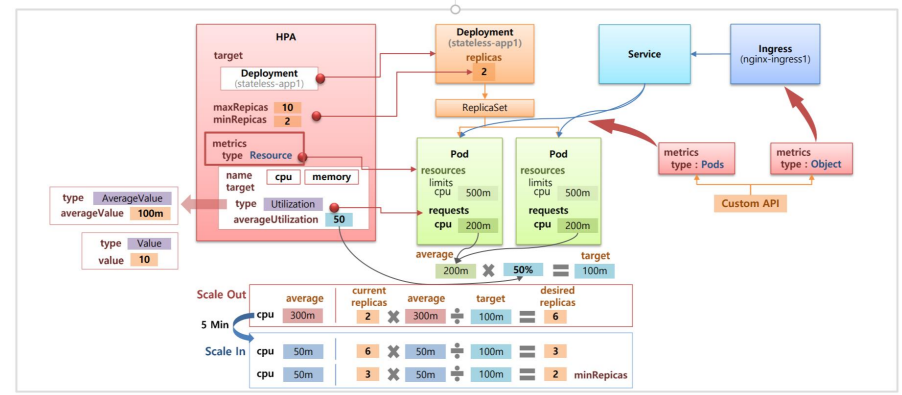
HPA 설정 값
설정값 설명 속성 sacleTargetRef : Deployment 지정</br>minReplicas : 최소 복제본 개수</br>maxReplicas : 최대 복제본 개수</br>(해당 파드는 minReplicas와 maxReplicas 범위 내의 개수가 생성됨) metrics 스케일링 조건 예제
구분 설명 Scale Out 두 Pod의 평균 Requests CPU가 200ms으로 설정되어 있을 때,</br>Type: Resource name: cpu로 설정되어 있기 때문에 AutoScale 기준은 CPU 사용율임</br>Type: Utilization averageUtilization: 50이므로 50% 넘으면 AutoScale 수행됨</br></br>즉, 50%를 실제 CPU 사용량으로 계산 시 200ms * 50% = 100ms이므로 </br>100ms이 넘게 되면 HPA는 replicas를 증가</br>두 Pod의 평균 CPU 사용량이 300ms으로 올라갔을 때, 예상되는 replicas 수는 6개임</br></br>[2(현재 replica수)*300ms(평균 CPU) / 100ms(target(200ms * 50%))] = 6 Scale In 6개의 Pod가 있는 상태에서 평균 CPU가 50ms으로 떨어지면</br></br>6개 * (50ms / 100ms) = 3개</br>3개 * (50ms / 100ms) = 1.5개 -> 2개(최소 Replica 수)
Storage
Container와 Kubernetes Volume 관계
구분 설명 개요 ✓ 모든 Container는 Container 이미지에서 제공하는 고유하게 분리된 파일 시스템을 가지고 있음</br>=> Container는 언제든 재시작될 수 있고 재시작된 Container는 새로운 Container이므로 기존 파일시스템은 사라짐</br>✓ Container의 기존 파일시스템이 유지되도록 하기 위해서는 Kubernetes Volume을 사용함 볼륨 ✓ 파드 로컬 볼륨 : 파드 안에만 만들어지는 볼륨</br>✓ 노드 로컬 볼륨 : 쿠버네티스 클러스터 노드의 볼륨</br>✓ 네트워크 볼륨 : 클러스터 외부에 존재하는 볼륨 Kubernetes Volume 특징
구분 설명 개요 ✓Pod에 종속되는 디스크로 Kubernetes에 의해 관리됨</br>✓ Pod 단위이기 때문에, 그 Pod에 속해 있는 여러 개의 컨테이너가 공유해서 Volume 사용</br>✓ 마운트 방식 : 로컬볼륨(EmptyDir, HostPath)와 네트워크 볼륨(직접지정, PV) 방식</br>✓ 로컬볼륨과 직접지정방식 모두 서비스 연속성 이슈 및 운영자에 의존성을 가지고 있어 PV 방식 선호 볼륨 ✓ emptyDir 볼륨 : 노드의 디스크에 생성 (메모리에 저장하는 tmpfs로도 생성 가능)파드가 삭제되면 볼륨과 이에 저장된 파일들 삭제</br>✓ hostPath 볼륨 : 노드의 파일 시스템 마운트</br>- 파드가 삭제되어도 볼륨에 저장된 파일들은 그대로 존재</br>- 노드의 파일 시스템을 마운트하기 때문에 파드가 다른 노드로 스케줄링 되면 이전 데이터를 볼 수 없음 구분 사용목적 파드 삭제시 볼륨 폐기 볼륨 유형 어플리케이션 어떤 처리를 위한 임시 공간 Y 파드 로컬 볼륨 - 컨피그맵, 시크릿, 파드 정보 참조 Y 파드 로컬 볼륨 - 파드가 실행된 노드의 파일 접근 N 노드 로컬 볼륨 - 특정 노드의 파일 접근 N 노드 로컬 볼륨 - 클러스터 외부 스토리지의 파일 접근 N 네트워크 볼륨 데이터베이스 컨피그맵, 시크릿, 파드 정보 참조 Y 파드 로컬 볼륨 - 파드가 실행된 노드에만 데이터 저장간 ㅜ 노드 로컬 볼륨 - 특정 노드에만 데이터 저장 N 노드 로컬 볼륨 - 클러스터 외부 스토리지에 데이터 저장 N 노드 로컬 볼륨 PV & PVC
| 개요 | 설명 |
|---|---|
| 개요 | ✓ 쿠버네티스에 애플리케이션을 배포하는 개발자는 어떤 종류의 스토리지 기술이 사용되는지 알 필요가 없어야 함</br>✓ 개발자가 운영자에 의존성을 가지지 않고 필요한 스토리지를 직접 Kubernetes에 요청하기 위해 PV 및 PVC 개념 |
| PV</br>(퍼시스턴트 볼륨) | 운영자는 미리 설정한 스토리지 볼륨을 Kubernetes에서 사용 가능한 Persistent Volume으로 구성 |
| PVC</br>(퍼시스턴트 볼륨 클레임) | 개발자가 어플리케이션에 필요한 용량 및 속성 요청 |
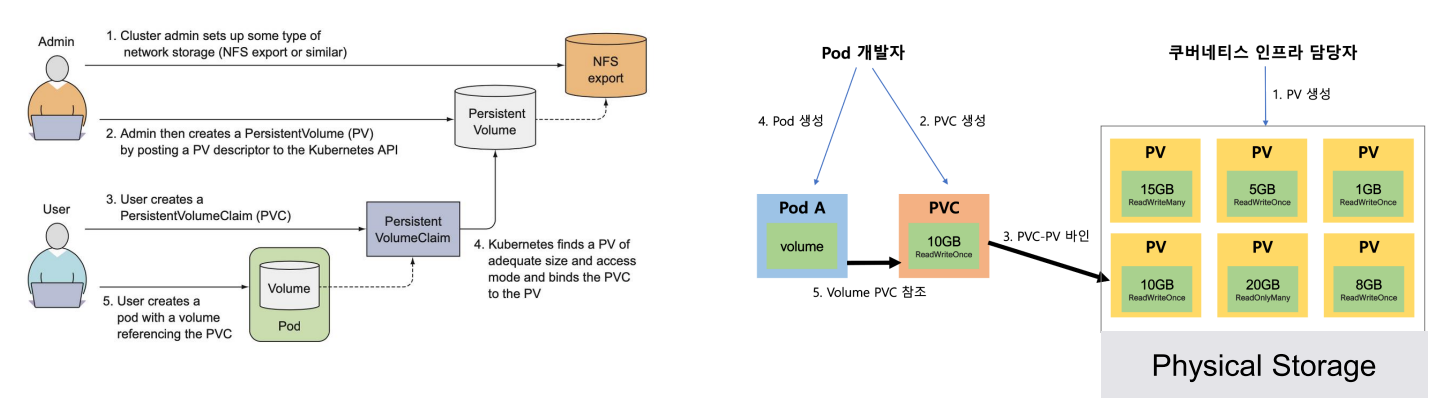
- PV 및 PVC를 통한 Volume 연결
| 구분 | 설명 |
|---|---|
| 생략 가능한 항목 | labels (사용 시 PVC의 Selector 항목에서 사용됨)</br>storageClassName (사용 시 PVC와 동일해야 함)</br>persistentVolumeReclaimPolicy</br>volumeMode |
| PV와 매칭되기 위한 조건 | 사용 시 바인딩 할 퍼시스턴트 볼륨 오브젝트의 값과 동일해야 함 (생략가능)</br>볼륨 요청 크기는 바인딩 할 PV에 지정한 용량보다 같거나 작아야 함 (PV와 PVC는 반드시 1:1로 매핑)</br>PV와 동일해야 함</br>사용 시 바인딩하고 싶은 PV의 labels와 동일해야 함(생략 가능) |
- PV Lifecycle
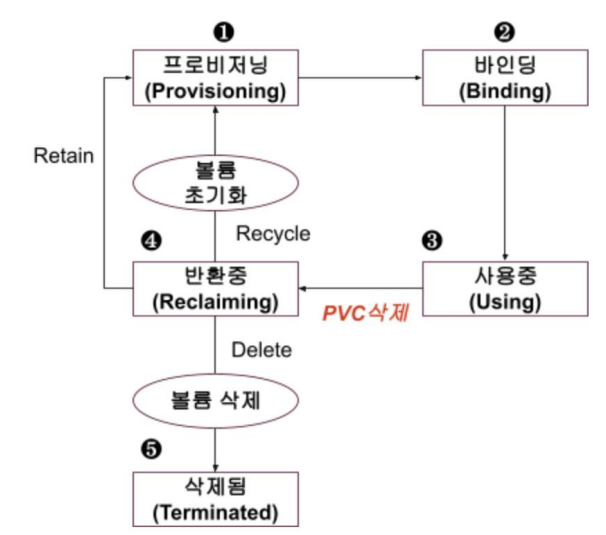
파드에 마운트 되어 사용중인 PV를 지우려면</br>
✓ 먼저 파드를 삭제하고 퍼시스턴트 볼륨 클레임까지 지워야 함.</br>
✓ 바인딩까지만 되어 있으면 PVC만 먼저 지우면 삭제할 수 있음.</br>
| 단계 | 설명 |
|---|---|
| [1] 프로비저닝 | 퍼시스턴트 볼륨 오브젝트에 정의된 대로 물리적인 볼륨이 프로비저닝(공급)되는 단계 |
| [2] 바인딩 | 퍼시스턴트 볼륨 오브젝트가 퍼시스턴트 볼륨 클레임 오브젝트와 연결되는 단계 |
| [3] 사용중 | 파드에 볼륨이 마운트 되어 볼륨을 사용하는 단계</br>파드 명세에 정의된 퍼시스턴트 볼륨 클레임과 바인딩된 퍼시스턴트 볼륨이 마운트 됨 |
| [4] 반환중 | 퍼시스턴트 볼륨 클레임 오브젝트가 삭제 되어 볼륨이 반환 되는 단계</br>퍼시스턴트 볼륨 오브젝트에 정의한 반환 정책(Reclaim Policy) 에 따라 다르게 처리</br></br>•Retain: PV는 프로비저닝 단계로 돌아가고 물리적 볼륨 데이터 유지. PVC와 바인딩 되려면 이전 바인딩 정보를 없애야 함</br>•Delete: PV가 자동으로 삭제되고 볼륨 종류에 따라 물리적 볼륨의 데이터도 삭제. 현재 물리적 볼륨 삭제가 되는 볼륨 종류: AWS EBS, GCE PD, Azure Disk</br>•Recycle: 볼륨 디렉토리 안의 파일들을 모두 삭제하고 프로비저닝 단계로 돌아감. 아무 작업 없이도 퍼시스턴트 볼륨 클레임과 바인딩 될 수 있음. Delete와 Recycle 반환 정책은 데이터가 사라질 수 있으니 주의 필요 |
| [5] 삭제 | 반환 정책이 Delete인 경우 퍼시스턴트 볼륨이 삭제</br>프로비저닝된 퍼시스턴트 볼륨을 바인딩 되기 전에 삭제하면 반환 정책과 상관 없이 물리 볼륨 데이터는 유지됨 |
- PV Lifecycle - PV 프로비저닝
| 구분 | 설명 |
|---|---|
| 개요 | PV를 만드는 단계</br>- Static 프로비저닝 : PV를 미리 만들어 두고 사용하는 정적(static) 방법</br>- Dynamic 프로비저닝 : 요청이 있을 때 마다 PV를 만드는 동적(dynamic) 방법 |
| 정적(static) 프로비저닝 | ✓ 클러스터 관리자가 미리 적정 용량의 PV를 만들어 두고 사용자의 요청이 있을 때 해당 PV를 할당</br>✓ 사용할 수 있는 스토리지 용량에 제한이 있을 때 유용</br>✓ 사용하도록 미리 만들어 둔 PV의 용량이 100GB라면 150GB를 사용하려는 요청들은 실패 |
| 동적(dynamic) 프로비저닝 | ✓ 동적으로 프로비저닝 할 때는 사용자가 PVC를 거쳐서 PV를 요청했을 때 생성해 제공</br>✓ 쿠버네티스 클러스터에 사용할 1TB 스토리지가 있다면 사용자가 원하는 용량만큼 생성해서 사용</br>✓ 정적 프로비저닝과 달리 필요하다면 한번에 200GB PV도 만들 수 있음</br>✓ PVC는 동적 프로비저닝할 때 여러가지 스토리지 중 원하는 스토리지를 정의하는 스토리지 클래스(Storage Class)로 PV를 생성 |
| - | PVC에 스토리지 클래스명을 지정하지 않았을 때 자동으로 동적 프로비저닝이 되게 하려면 생성한 스토리지 클래스를 기본 클래스로 생성 |
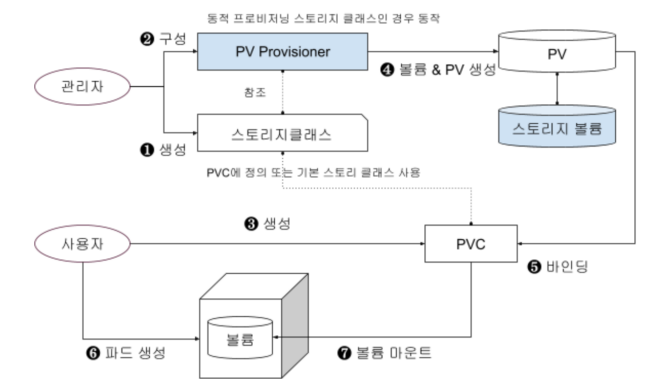
| 단계 | 설명 |
|---|---|
| [1] | 동적 프로비저닝을 위한 동적 프로비저너를 파드로 설치 |
| [2] | 관리자는 동적 프로비저닝을 지원하는 스토리지 클래스를 미리 생성 필요 |
| [3] | 볼륨 사용자가 퍼시스턴트 볼륨 클레임 오브젝트를 생성 |
| [4] | 동적 프로비저너는 PVC에 정의되어 있는 스토리지 클래스의 내용 참조하여 스토리지 볼륨에 볼륨을 생성하고 퍼시스턴트 볼륨 오브젝트도 생성됨 |
| [5] | PV와 PVC 바인딩 됨 |
| [6,7] | 진행 |
| - | 동적 프로비저닝을 사용하려면 각 스토리지 제품에 맞는 CSI 드라이버가 설치되어야 함 |
- Volume 구분
| 접근모드 | 설명 |
|---|---|
| ReadWriteOnce | ReadWriteOnce: RWO-한 노드에서만 볼륨 마운트를 할 수 있고 읽기/쓰기 허용 |
| ReadWriteMany | RWX- 여러 노드에서 볼륨 마운트를 할 수 있고 읽기/쓰기 허용 |
| ReadOnlyMany | ROX-여러 노드에서 볼륨 마운트를 할 수 있고 읽기만 허용 |
| ReadWriteOncePod | RWOP-한 파드에서만 볼륨 마운트를 할 수 있고 읽기/쓰기 허용 |
| 벤더 | 제품명 | 쿠버네티스 사용명 | 볼륨확장 | RWO | ROX | RWX |
|---|---|---|---|---|---|---|
| 아마존 AWS | AWS EBS(Elastic Block Store) | awsElasticBlockStore | O | O | X | X |
| MS Azure | Azure Disk | azureDisk | O | O | X | X |
| - | Azure File | azureFile | X | O | O | O |
| 구글 GCP | GCE PD(Persistent Disk) | gcePersistentDisk | O | O | O | X |
| 레드햇RedHat | GlusterFS | GlusterFS | O | O | O | O |
| 포트웍스Portworx | Portworx Volume | portworxVolume | O | O | X | O |
| VMWare | vSphere Volume | vsphereVolume | X | O | X | X |
| Ceph | Ceph FS | cephfs | X | O | O | O |
| - | Ceph RBD | rbd | O | O | O | X |
| 기타 | CSI | csi | O | △ | △ | △ |
| - | NFS | nfs | X | O | O | O |
| - | FlexVolume | flexVolume | O | O | O | X |
| - | FC | fc | X | O | O | X |
| - | iSCSI | fc | X | O | O | X |
- for Test
$\left\lvert \frac{s^2+1}{s^3+2s^2+3s+1} \right\rvert$
Networking
- Pod Network 구성: “Pod 안의 Container는 네트워크 스택을 공유한다”
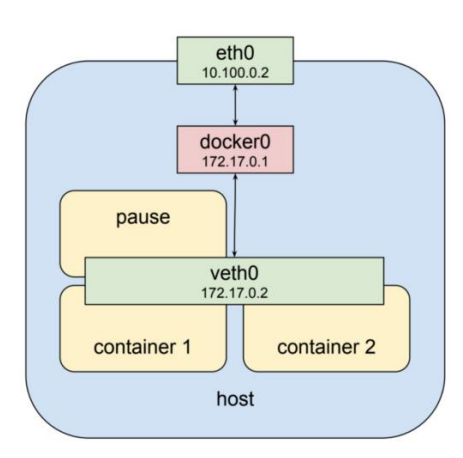
| 구분 | 설명 |
|---|---|
| 네트워크 | 운영자가 설정하는 대역은 eth0</br>즉, 운영자는 10.100.0.2 대역은 알고 있지만 나머지는 모름</br></br>172.17.0.X 대역은 Kubernetes에 의해서 자동 생성</br>-> 외부에서 172.17.0.x 대역을 어떻게 알고 트래픽을 보낼 수 있을까? |
| Pause Container | 같은 Pod의 Container들이 동일한 Linux Namespace를 공유할 수 있도록 함</br>서로 다른 Container 및 바깥과의 통신을 담당하는 핵심 Container |
- CNI (Container Network Interface): CNI는 오직 “컨테이너의 네트워크 연결성” 과 “컨테이너 삭제시 관련된 네트워크 리소스 해제” 에 대해서만 관여
CNI에 대해 알아야할 기본 상식
순번 내용 1 CNI는 Container에 대한 Network 정의로 K8s에서만 동작하는 것이 아님! 2 k8s에서는 Pod에서 동작함 (Container 개별이 아닌 PoD임) 3 CNI plugin은 컨테이너 네트워크 연결에 책임을 가짐</br>(컨테이너가 네트워크에 연결되기 위한 모든 작업에 대한 책임) 4 CNI plugin은 IPAM(IP 할당관리)에 책임 5 IP주소 할당 뿐만 아니라 적절한 라우팅 정보를 입력하는 것까지 포함</br>(Kube-proxy는 Pod to Pod 통신에 관여하지 않음, 이 역할은 CNI와 노드에서 필요한 라우팅 설정)
- Pod Network 구성
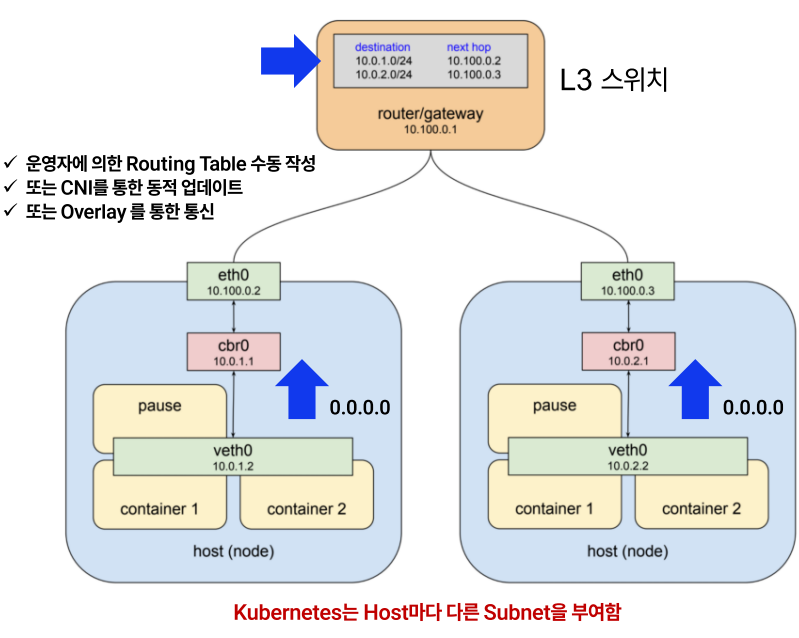
| 이슈 | 설명 |
|---|---|
| 이슈#1 | Host마다 Pod 네트워크가 다름.</br>Pod가 죽고 다시 실행되면 같은 Host에 배포될 가능성 낮음</br></br>즉, Pod의 IP가 변함</br>그렇다면 L3로 Routing을 잡아도 해당 Pod가 어디에 있는지 모름 |
| 이슈#2 | 동일한 기능을 수행하는 Pod가 기본적으로 여러 개 생성됨</br>Pod의 위치와 상관없이 지속적인 통신이 이루져야 함</br></br>즉, 여러 개의 Pod에 하나의 IP를 통한 단일 진입점이 필요함</br>그렇다면, VIP 제공이 필요 => SLB 요구 사항과 동일함 |
| - | Service라는 컴포넌트 필요! |
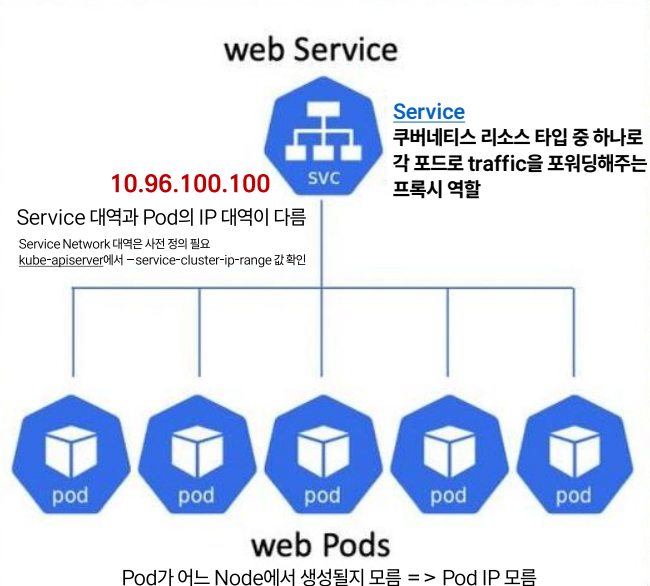
| 목적 | 서비스유형 |
|---|---|
| 클러스터 내부 간 통신 | ClusterIP - 클러스터 내의 모든 Pod가 해당 Cluster IP 주소로 접근 가능 |
| 클러스터 외부와 내부통신 | NodePort |
| 클라우드벤더의 로드밸런서 이용 | LoadBalancer |
| 클라우드 외부로의 프록시 역할 | ExternalName |
- Service Network 구성 – ClusterIP
| 구분 | 설명 |
|---|---|
| 개요 | Cluster IP인 10.3.241.152은 어디서도 모르는 IP임</br>(Pod IP도 아니고 Gateway에 등록된 IP도 아님) |
| 특징 | ✓ Cluster IP는 클러스터 내부 Pod에서 시작되는 통신에 적합함</br>✓ 외부에서 오는 요청에는 적합하지 않음 (Origin IP 변경 등) |
| kube-proxy | - 관리자가 별도의 작업을 수행하지 않아도 Kubernetes 오브젝트들 간에 통신이 이루어질 수 있도록 네트워크 룰 설정</br>- NodePort와 같이 외부로 노출되는 port들을 오픈 |
- Service Network 구성 – NodePort & Loadbalancer
| 구분 | 내용 |
|---|---|
| Cluster IP 제약 사항 | ✓ Cluster IP는 L3 Layer로 실제 해당 프로세스가 정상 동작하는지 확인할 수 있는 방법이 없음 (Layer 4 헬스 체크 필요 : Http – TCP 80 등)</br>✓ Cluster 내 Pod에서 시작되는 통신에 대해 Kube-Proxy에서 실제 Pod IP로 NAT 시키는 방식이기 때문에 외부 통신에 취약</br>=> 이를 해결하기 위해 Node Port, Load Balancer, Ingress 방식 소개됨. |
| NodePort 기본 동작 방식 | ✓ NodePort 서비스 생성 (포트 번호 30000-32767 사이가 초기 값임)</br>✓ 해당 NodePort 포트 번호는 서비스에 연결된 Pod가 있던 없던 모든 Node에 설정됨</br>✓ 아무 Node에나 Node Port 포트 번호로 요청이 오면 이를 Cluster IP로 전달함 |
| 외부 통신을 위해 Node Port 설정 시 외부 Load Balancer</br>(강력 권장) | ✓ NodePort의 포트 번호가 표준 포트 번호가 아님</br>=> SLB NAT를 통해 포트 번호 이슈 해결 필요</br>✓ Source IP가 가려짐 (Origin IP 변경)</br>=> 외부 SLB를 통해 Origin IP 확보 필요</br>=> NodePort 사용 시 내/외부 상관없이 Load Balancer 권장 |
| LoadBalancer Service type 특징 | ✓ 동작 방식은 외부 Load Balancer 연동과 비슷함</br>✓ NodePort에 외부 Load Balancer를 사용할 때는 수동 설정 필요.</br>Load Balancer Service Type은 자동 설정이 많음</br>✓ 서비스 생성과 함께 Load Balancer 새롭게 생성됨</br>✓ Public Cloud 환경에서 주로 사용됨 / Private은 MetalLB 사용 |
| 외부에서 내부 통신하는 절차 | 1 Load Balancer 설정: Virtual IP - 공인 IP와 클라이언트 요청 포트번호 등록 / Real IP – 모든 Node eth0와 Node Port 포트번호 등록</br>2 (NAT) 해당 공인 IP와 포트번호로 요청이 오면 Load Balancer는 등록된 Node 중 하나에 Node Port 포트 번호로 전송</br>3 (NAT) 요청 받은 Node는 Kube-Proxy에서 Cluster IP로 변환</br>4 (NAT) 해당 Pod가 있는 Node로 연결 전 Cluster IP는 해당 Pod IP로 변환</br>5 통신 |
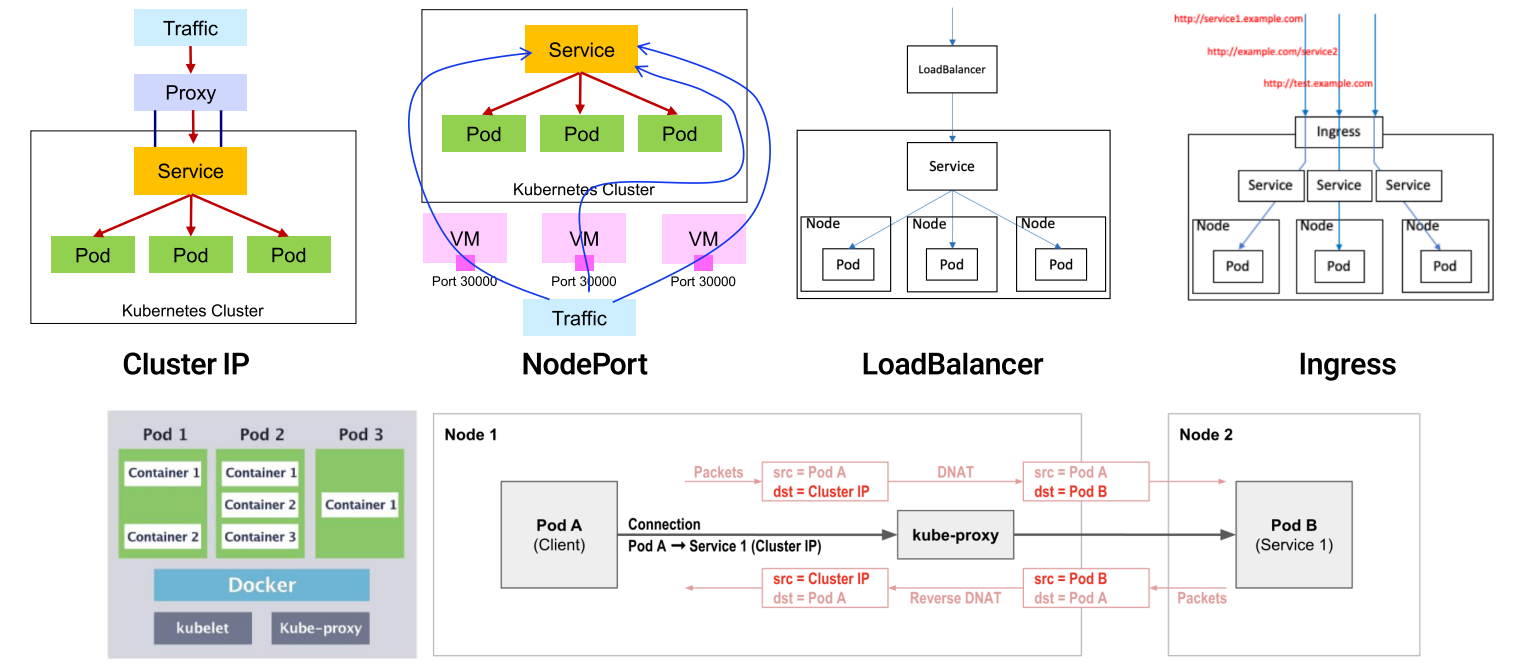
| 종류 | 특징 | 사용시기 |
|---|---|---|
| ClusterIP | ClusterIP 서비스는 k8s 기본 서비스로 클러스터 내의 다른 앱이 접근 가능하도록 함.</br>ClusterIP는 외부 접근 불가. </br>k8s 내에 Proxy 설정을 통해 외부에서 접근 가능 | 서비스를 디버깅하거나 특정사유로 PC 에서 직접 접근할 때</br>내부 대시보드 표시 등 내부 트래픽을 허용할 때 |
| NodePort | NodePort 서비스는 Pod가 탑재된 Node에 접근할 수 있는 포트를 외부로 노출시켜주는 포트</br>NodePort는 30000~32767 사이의 포트를 사용 | 포트 당 1개 서비스만 할당 가능</br>30000~32767 사이의 포트만 사용 가능</br>비용에 민감하거나 항상 운용하는 서비스가 아니라면 사용 추천 |
| LoadBalancer | LoadBalancer 서비스는 서비스를 인터넷에 노출하는 일반적인 방식</br>GKE의 경우 Network Load Balancer를 작동시켜 모든 트래픽을 서비스로 포워딩하는 단 하나의 IP주소를 제공 | 서비스를 직접적으로 노출하기 원할 경우</br>필터, 라우팅이 필요 없을 때.DMZ 등의 API Gateway 등과 통합할 때. </br>단, 노출하는 서비스마다 자체IP를 가지게 된다는 것과 노출되는 서비스 마다 LoadBalancer 비용을 지불해야하는 것이 부담 |
| Ingress | Ingress는 Cluster, NodePort, LoadBalancer와 달리 서비스가 아님</br>L7 수준의 Load Balancing 기능을 수행</br>End Port 역할</br>가장 강력한 외부로의 서비스 노춟방식이지만 가장 복잡한 방식임 | Nginx, Contour, ELB, Google Cloud Load Balancer, Kong 등이 유명</br>다양한 부가기능이 필요할 떼 (제품에 따라 트래픽 제어, 필터링, 로드밸런싱, SSL, Auth 등 가능) |
#include <stdio.h>
int main()
{
return 0
}